CHI 97 Electronic Publications: Late-Breaking/Short Talks
Searching and Browsing Text Collections with Large Category
Hierarchies
Marti A. Hearst
Xerox Palo Alto Research Center
3333 Coyote Hill Rd
Palo Alto, CA 94304 USA
hearst@parc.xerox.com
Chandu Karadi
School of Medicine, M121
Stanford University
Stanford, CA 94305 USA
karadi@leland.stanford.edu
ABSTRACT
A new user interface has been developed that allows users to make use
of large category hierarchies for search and browsing of retrieval
results for information access. The key insight is the separation of
the representation of category labels from documents, which allows the
display of multiple categories per document.
Keywords
Information Access, Information Visualization, Text, Search,
Categories.
© 1997 Copyright on this material is held by the authors.
INTRODUCTION
A query against an information access system often results in a result
set consisting of a large number of documents. Interfaces are needed
to help users make sense of the their retrieval results. One tack is
to graphically show the relationship between the query and the
retrieved documents, as is done in the TileBars interface
[5]. Another approach is to group the documents
according to their overall similarity to one another as seen in the
Scatter/Gather system [3]. A third option is to classify
the documents according to semantic attributes and display these
attributes in a useful way.
Some attributes that are often associated with documents, (sometimes
called meta-data) describe aspects of the external properties of the
document, including author, date of creation, provenance, document
length, language, and so on. Certain recent interfaces, including
Envision [4] and SenseMaker [1], have focused
on allowing the user to see which documents are associated with
various combinations of this kind of information.
Another kind of attribute information has to do with the actual
content of meaning of the documents. These attributes are often
called category labels or subject codes (e.g., in bibliographic
collections, such as seen in the Dewey Decimal system). Some online
text collections now have associated with them very large, complex
sets of category labels. For example, the Association for Computing
Machinery (ACM) has associated with it a large subject hierachy
consisting of approximate 1200 labels. These category labels (e.g.,
Hardware Description Languages, Image Processing) are assigned
by authors to their journal articles in order to indicate the subject
matter of the documents, averaging approximately three to five
categories per document.
Once these labels are available, how should a text retrieval system
provide access to a text collection that has associated with it a
large hierarchy of categories? In most systems, and in many World
Wide Web interfaces, the user must scroll through a list of categories
to find those of interest. The user is usually not given an overview of
the category space other than a top-level view of the most general
labels. If the system does let the user search over the names in the
category labels, the results are typically shown as an alphabetical
list, with corresponding documents listed under the corresponding
category labels.
Thus these approaches do not show users the context in which the
category labels or are used within the documents, and make navigation
of very large category hierarchies difficult. Futhermore, if
documents have been assigned multiple categories, most interfaces
provide no mechanism for helping the user make use of the multi-part
description of the document's contents.
SEPARATING CATEGORIES FROM DOCUMENTS
We think the key problem with existing systems is that they do not
make a clear distinction between searching for categories and
searching for documents. We have developed an interface, called the
Cat-a-Cone (see Figure 1), that makes use of the
insight that the representation of the categories should be separated
from but linked to that of the documents [6]. The
Cat-a-Cone uses an existing information visualization environment (IV)
[8] in a novel way.
To achieve the separation between category labels and documents,
category labels are placed in a ConeTree [8], and after
a search over free text words or category labels, retrieval results a
placed in a virtual book [2]. By contrast, in most systems
that present graphical hierarchies, documents are associated with each
node of the category hierarchy; clicking on a node reveals the
documents assigned this node. In the Cat-a-Cone, documents as
associated with searches. When the user opens up a ``page'' of the
retrieval results, the parts of the hierarchy that correspond to the
set of categories that have been assigned to the document are shown in
the ConeTree. The virtual book allows the user to ``flip'' through a
set of pages, and this causes differences among documents to be
animated in terms of which parts of the hierarchy remain present,
which shrink away, and which sprout out.
The use of the ConeTree also enables the user to see the context in
which the category labels occur. Thus the meaning of unfamiliar or
ambiguous categories can be made clearer by display of their
ancestors, siblings, and immediate descendants. Different subtrees of
the hierarchy can be displayed at different levels of granularity
depending on the familiarity to the user.
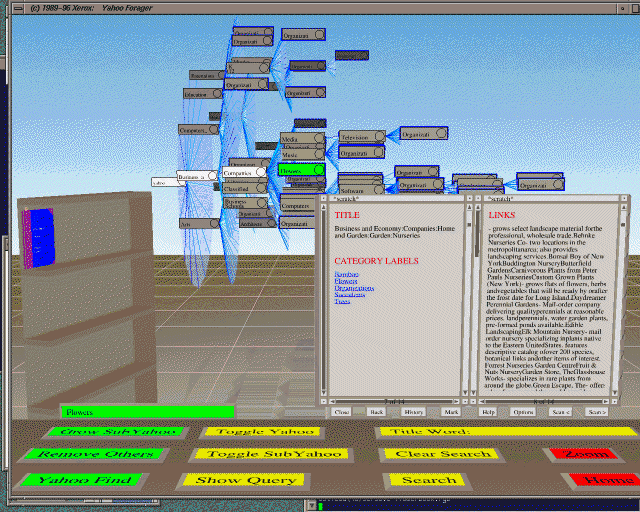
Figure 1: The Cat-a-Cone interface applied to the Yahoo
hierarchy.
SPECIFYING QUERIES
Research has shown that a combination of category labels with free
text works better than either alone [9, 7]. We have
developed a novel technique for allowing users to specify queries in
terms of a Boolean combination of category labels and free text. The
user first chooses a color from a palette. Every subtree painted with
that color is considered one element of a disjunct. Each color
represents a different element of a conjunct. The user types free
text into an entry form marked with colors from the palette. So the
user in effect specifies queries of the that they can think of in
terms of: ``at least one blue item, at least one green item, and at
least one yellow item''. The NOT operator is indicated with a
reserved color (black).
The Cat-a-Cone is not meant to be a stand-alone system, but rather
part of a suite of tools each designed to help with a different aspect
of the information access problem. We plan to evaluate the usefulness
of our ideas on medical text using as subjects cancer patients and
clinicians.
References
- 1
-
Michelle Q. Wang Baldonado and Terry Winograd.
Sensemaker: An information-exploration interface supporting the
contextual evolution of a user's interests.
In Proceedings of the ACM SIGCHI Conference on Human Factors in
Computing Systems, 1997.
To appear.
- 2
-
Stuart K. Card, George G. Robertson, and William York.
The webbook and the web forager: An information workspace for the
world-wide web.
In Proceedings of the ACM SIGCHI Conference on Human Factors in
Computing Systems, Vancouver, Canada, April 1996.
- 3
-
Douglass R. Cutting, Jan O. Pedersen, David Karger, and John W. Tukey.
Scatter/Gather: A cluster-based approach to browsing large document
collections.
In Proceedings of the 15th Annual International ACM/SIGIR
Conference, pages 318-329, Copenhagen, Denmark, 1992.
- 4
-
Edward A. Fox, Deborah Hix, Lucy T. Nowell, Dennis J. Brueni, William C. Wake,
Lenwwod S. Heath, and Durgesh Rao.
Users, user interfaces, and objects: Envision, a digital library.
Journal of the American Society for Information Science,
44(8):480-491, 1993.
- 5
-
Marti A. Hearst.
Tilebars: Visualization of term distribution information in full text
information access.
In Proceedings of the ACM SIGCHI Conference on Human Factors in
Computing Systems, Denver, CO, May 1995.
- 6
-
Marti A. Hearst and Chandu Karadi.
Cat-a-cone: An interative interface for specifying searches and
viewing retrieval results using a large category hierarchy.
1997.
Submitted for publication.
- 7
-
William R. Hersh, David H. Hickman, Brian Haynes, and K. Ann McKibbon.
A performance and failure analysis of saphire with a medline test
collection.
Journal of the American Medical Informatics Association,
1(1):51-60, 1994.
- 8
-
George C. Robertson, Stuart K. Card, and Jock D. MacKinlay.
Information visualization using 3D interactive animation.
Communications of the ACM, 36(4):56-71, 1993.
- 9
-
Padmini Srinivasan.
Optimal document-indexing vocabulary for medline.
Information Processing and Management, 32(5):503-514, 1996.
CHI 97 Electronic Publications: Late-Breaking/Short Talks


